Engineering
Written by Memori Team
Releasing Our LoCoMo Benchmark Paper: Memori Labs Outperforms the Competition - Hits 81.95% Accuracy at 4.98% the cost of Full Context
Today, we're releasing a new white paper: Memori: A Persistent Memory Layer for Efficient, Context-Aware LLM Agents.
The paper focuses on a simple question that matters for every production AI team: how do you give agents durable memory without flooding the prompt with raw chat history?
Our answer is that memory should be treated as a data structuring problem, not a context stuffing problem.
What the paper shows
We evaluated Memori on the LoCoMo benchmark, a long-conversation memory benchmark designed to test whether systems can retain and reason over information spread across noisy, multi-session chat histories.
Memori achieved 81.95% overall accuracy on LoCoMo while using an average of just 1,294 tokens per query — only 4.98% of the full conversation context.
Here's how that compares to other retrieval-based memory systems and the full-context ceiling:
| Table 1: LLM-as-a-Judge Evaluation Results on the LoCoMo Benchmark | |||||
|---|---|---|---|---|---|
| Method | Single-hop (%) | Multi-hop (%) | Open-domain (%) | Temporal (%) | Overall (%) |
| Memori | 87.87 | 72.70 | 63.54 | 80.37 | 81.95 |
| Zep | 79.43 | 69.16 | 73.96 | 83.33 | 79.09 |
| LangMem | 74.47 | 61.06 | 67.71 | 86.92 | 78.05 |
| Mem0 | 62.41 | 57.32 | 44.79 | 66.47 | 62.47 |
| Full-Context (Ceiling) | 88.53 | 77.70 | 71.88 | 92.70 | 87.52 |
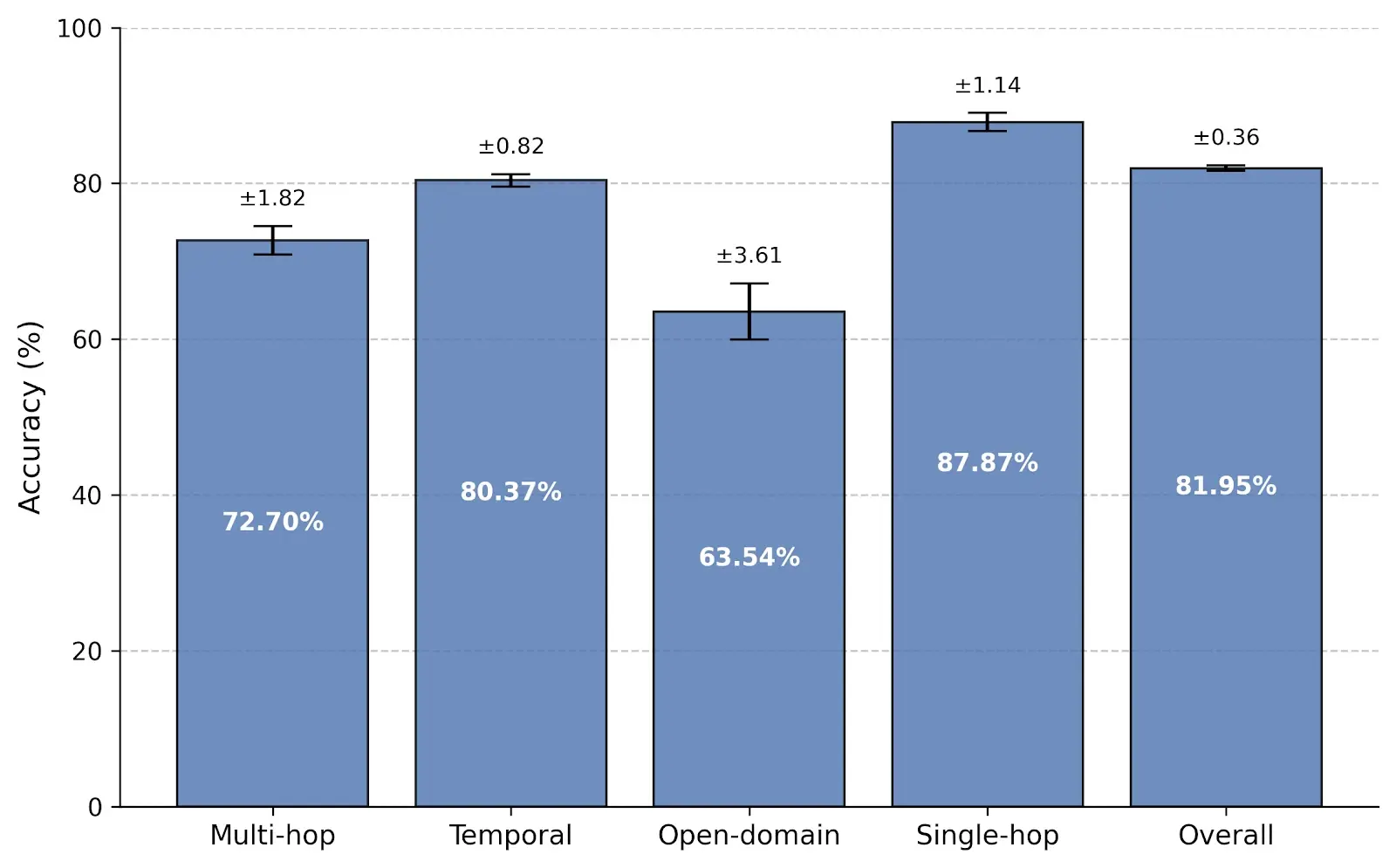
Memori outperforms Zep, LangMem, and Mem0 across overall accuracy. It leads in single-hop and multi-hop reasoning, and closes the gap to the full-context ceiling — all while using a fraction of the tokens.
The cost story is just as important:
| Table 2: Token Usage and Cost Efficiency | |||
|---|---|---|---|
| Method | Added Tokens to Context (mean) | Context Cost ($) | Context Footprint (%) |
| Memori | 1,294 | 0.001035 | 4.97 |
| Full-context | 26,031 | 0.020825 | 100.00 |
| Mem0 | 1,764 | 0.001411 | 6.78 |
| Zep | 3,911 | 0.003129 | 15.02 |
That's 67% fewer tokens than Zep and over 20x cheaper than full-context prompting. You do not need to choose between memory quality and operating cost as aggressively as most teams assume.
Why this matters
Most memory systems still rely on some variation of raw transcript retrieval. That approach creates three problems fast:
- too many tokens pushed into the prompt
- too much conversational noise in retrieval
- weaker reasoning as histories grow longer and harder to use
Memori takes a different approach. Instead of storing memory as large chunks of raw conversation, Memori's Advanced Augmentation pipeline turns conversations into two high-signal memory assets:
- Semantic triples: compact subject-predicate-object facts extracted from conversation, optimized for precise vector search and minimal token footprint
- Session summaries: concise narrative overviews that capture intent, chronological progression, and how goals evolved during an interaction
That dual structure is the core idea behind the paper. Triples help the model recover exact facts efficiently. Session summaries help the model understand how goals, preferences, and states changed over time. Together, they explain why Memori performs especially well on single-hop retrieval (87.87%) and temporal reasoning (80.37%).
How we evaluated it
The paper walks through the benchmark setup in detail:
- LoCoMo conversations were processed through Memori's Advanced Augmentation pipeline
- extracted triples were embedded with Gemma-300
- memories were indexed locally with FAISS
- retrieval used a hybrid of embedding similarity and BM25
- answers were generated with GPT-4.1-mini
- results were scored with an LLM-as-a-Judge evaluation flow
- Memori performance values were computed using the average of three rounds
We also compared accuracy against token consumption, because benchmark quality without cost discipline is not enough for production systems.
The bigger takeaway
The biggest takeaway from the paper is not just that Memori outperformed the competition on the LoCoMo benchmark.
It's that better memory comes from better structure, not from throwing larger and larger context windows at the model.
For teams building agents, copilots, and multi-session AI products, that matters operationally:
- lower inference cost
- less prompt bloat
- better cross-session continuity
- more reliable recall of facts, preferences, and evolving context
Read the paper
The full paper goes deeper into the architecture, evaluation setup, category-level results, and token-efficiency analysis. Read it here.