LoCoMo Benchmark Overview
As large language models (LLMs) evolve into autonomous agents, persistent memory at the API layer is essential for enabling context-aware behavior across LLMs and multi-session interactions. Existing approaches force vendor lock-in and rely on injecting large volumes of raw conversation into prompts, leading to high token costs and degraded performance.
We introduce Memori, a LLM-agnostic persistent memory layer that treats memory as a data structuring problem. Its Advanced Augmentation pipeline converts unstructured dialogue into compact semantic triples and conversation summaries, enabling precise retrieval and coherent reasoning.
Evaluated on the LoCoMo benchmark, Memori achieves 81.95% accuracy, outperforming existing memory systems while using only 1,294 tokens per query (~5% of full context). This results in substantial cost reductions, including 67% fewer tokens than competing approaches and over 20× savings compared to full-context methods.
These results show that effective memory in LLM agents depends on structured representations instead of larger context windows, enabling scalable and cost-efficient deployment.
Introduction
In recent years, large language models (LLMs) have rapidly evolved into fully sophisticated AI agents. These foundation-model-powered systems have demonstrated strong performance across diverse domains, including research, software engineering, and scientific discovery, pushing the trajectory toward more general and adaptive intelligence. As the field matures, it is evident that modern agents extend beyond a pure LLM backbone and incorporate additional capabilities such as reasoning, planning, perception, memory, and tool use. Together, these components transform LLMs from static conditional generators into adaptive systems capable of interacting with external environments and improving over time.
Large language models (LLMs) have quickly become sophisticated AI agents. These foundation-model-powered systems perform well in research, software engineering, and scientific discovery, driving the move toward general intelligence. Modern agents now go beyond using only LLMs by adding reasoning, planning, perception, memory, and tool use. These components let LLMs act as adaptive systems that interact with their environments and improve over time.
Among these capabilities, memory stands out as a foundational pillar. Unlike reasoning or tool use, which are increasingly internalized within model parameters, memory remains largely dependent on external system design. This dependency arises because LLM parameters cannot be updated in real time during deployment. Memory mechanisms, therefore, play a key role in enabling agents to persist information across interactions, adapt to user context, and evolve based on experience.
This reliance on external memory is especially apparent from an application perspective: persistent memory is essential. Domains such as personalized assistants, recommendation systems, social simulations, and complex investigative workflows all require agents to retain and reason over historical information. Without memory, these systems behave as stateless responders, repeatedly reprocessing context and failing to build continuity over time. From a broader research perspective, agents’ ability to continually evolve through interaction is central to the pursuit of general intelligence. This capacity is fundamentally grounded in memory
Enabling long-term, cross-session, cross-model memory introduces significant challenges. Naively storing and injecting past interactions into the prompt leads to rapidly growing context windows. This increases both cost and instability. As context size grows, models become more prone to overlooking critical information. They may produce inconsistent outputs and suffer from what is commonly referred to as context rot, in which relevant information is present but not effectively used.
These limitations highlight a key insight: memory in LLM systems is not simply a storage problem, but a structuring problem. The challenge is to transform noisy, unstructured conversational data into representations that are efficient to retrieve. These representations must also be effective for downstream reasoning.
Memori implements this as a persistent memory layer that incrementally distills conversational data into structured representations. This process is handled by Advanced Augmentation, a memory creation pipeline that extracts, compresses, and organizes high-signal information from raw interactions for efficient retrieval and downstream use. Through empirical evaluation on the LoCoMo benchmark, we demonstrate that high-quality memory structuring enables strong reasoning performance while dramatically reducing the number of tokens required in the prompt, thereby improving the cost-efficiency and scalability of LLM agents.
System Architecture
As depicted in Figure 1, Memori operates as a decoupled memory layer positioned between the application logic and the underlying LLM. The system integrates via a lightweight Memori SDK, seamlessly wrapping existing LLM clients to intercept requests and manage memory natively.
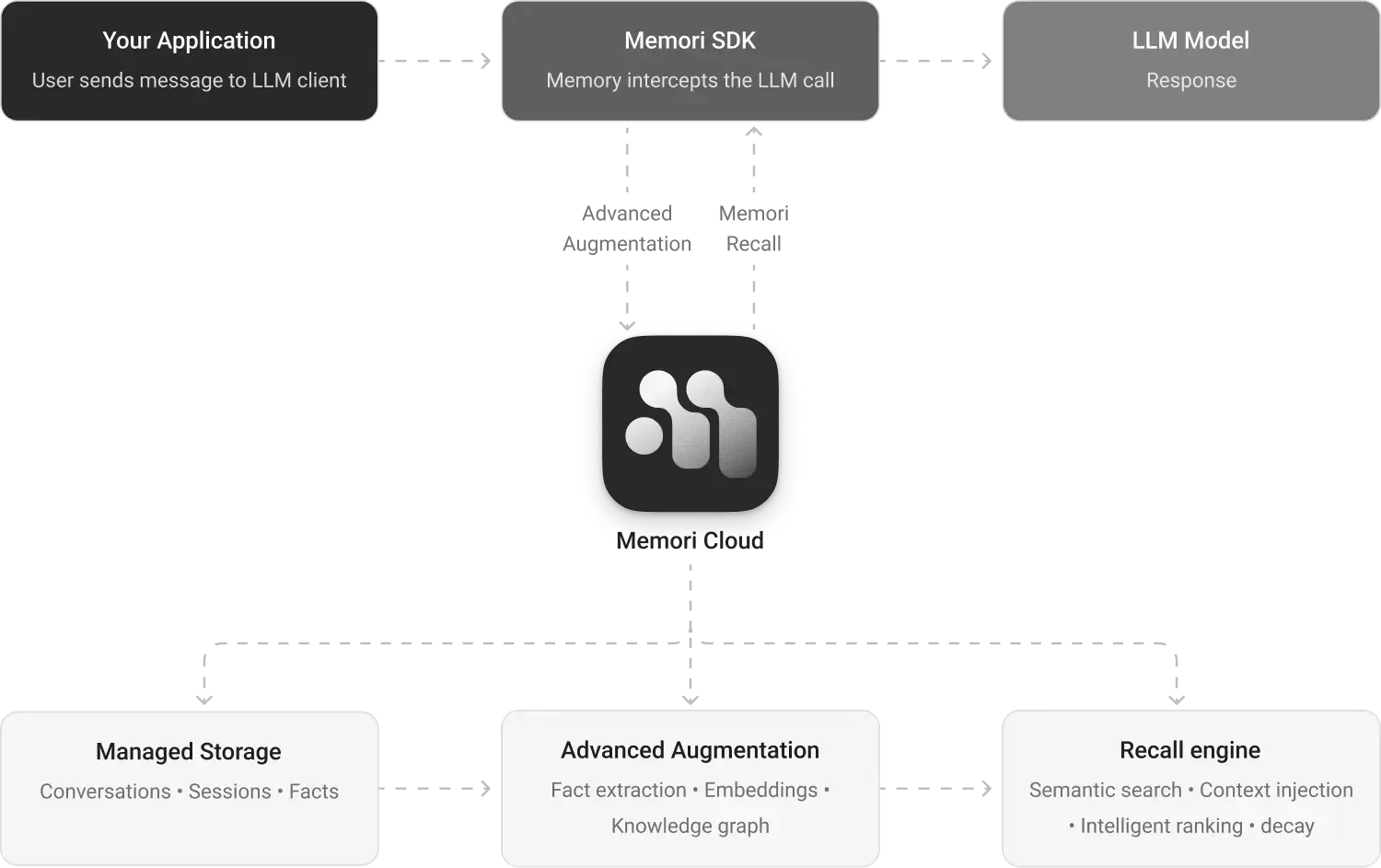
The core differentiators of the Memori architecture lie in how it structures unstructured data and how it intelligently retrieves that data for reasoning.
Advanced Augmentation: Structuring the Unstructured
Raw conversation logs are noisy, filled with colloquialisms, pleasantries, self-corrections, and tangential discussions. When these raw, unstructured transcripts are directly chunked and embedded, as is standard in traditional RAG architectures, the resulting vector space becomes heavily cluttered. Direct retrieval from this noisy data is highly inefficient, leading to false positives, contradictory context, and massively inflated token consumption during the generation phase.
To solve this, Advanced Augmentation functions as an automated cognitive filter. It is a background memory creation pipeline designed to distill raw dialogue into searchable memory assets, shifting the system's memory from mere text storage to an organized knowledge base.
- Semantic Extraction & Triple Generation: Rather than saving sentences, the pipeline deconstructs dialogue messages into atomic units of knowledge. It actively scans conversations for concrete facts, user preferences, constraints, and evolving attributes, structuring them into semantic triples (subject–predicate–object). Each triple is then linked to the exact conversation in which it was mentioned. This design delivers two key advantages. First, it produces a low-noise, high-signal index that improves vector search retrieval accuracy. Second, it functions as a compression layer.
- Conversation Summarization: While semantic triples excel at capturing granular, static facts, they inherently strip away the surrounding context. An isolated triple might state what a user prefers, but it lacks the narrative of why a decision was made or how a user’s goal evolved throughout a specific interaction. To bridge this gap, the pipeline simultaneously generates Conversation Summaries. These are concise, high-level overviews of specific conversational threads that capture the user’s overarching intent, the dialogue's chronological progression, and the task's implicit context. Because triples are tied to their source, each individual triple can be directly linked to the proper summary of the conversation in which it appears, allowing the system to easily retrieve the background story behind any isolated fact.
Advanced Augmentation creates an interconnected, dual-layered memory asset: Triples provide the precise, token-efficient facts needed for exact recall, while Conversation Summaries provide the cohesive narrative flow required for the LLM to understand temporal changes and execute complex reasoning. By linking atomic triples directly to the summaries of the conversations they originated from, the system ensures that granular facts are never divorced from their broader context.